Ваш uplift – випадковість: що не так із A/B тестами продуктів
A/B тести вже давно стали золотим стандартом продуктової розробки. Близько 80% компаній в усьому світі проводять такі тестування для своїх вебсайтів. Вони створюють відчуття контролю: є варіант А, є варіант B, є цифри, які показують різницю між ними – значить є відповідь.
Це дійсно дієвий інструмент для певних завдань. Та проблема в тому, що A/B тести часто не дають тих відповідей, які насправді хвилюють бізнес.
Наприклад, команда хоче зрозуміти, чи дасть зміна реальний ефект у виторгу, поведінці, частоті та retention. Проводить тестування і отримує відповідь на зовсім інше питання: чи є різниця між варіантами в короткостроковій перспективі.
Чому так стається і що робити? У колонці для Scroll.media пояснює Дмитро Москаленко, Chief Product & Technology Officer в MAUDAU.

Чому uplift у тесті не гарантує результат після релізу
Багато хто стикався з такою ситуацією: A/B тест показав зростання метрик, фічу розкотили на всіх користувачів – та в результаті не отримали помітного ефекту на рівні бізнесу. Наприклад, тому що фактичний рівень використання фічі виявився значно нижчим за очікуваний.
Коли ми запускаємо тест, ми дивимось на дуже вузький зріз реальності: обмежений період, обмежена аудиторія і набір метрик, які ми вирішили вимірювати. Це контрольований експеримент, але він не дорівнює реальному життю продукту — ні в контексті (бо середовище штучно відтворене), ні в масштабі впливу (бо тест не проходить через всю аудиторію і весь життєвий цикл користувача).
Користувач у тесті поводиться інакше. Є ефект новизни, підвищений фокус уваги, відсутність сформованої звички. І те, що виглядає як покращення в перші дні, дуже часто не переживає час. Саме через це те, що працювало в тестовому режимі, може показати зовсім інший результат в реальності.
Часті помилки при дизайні тесту
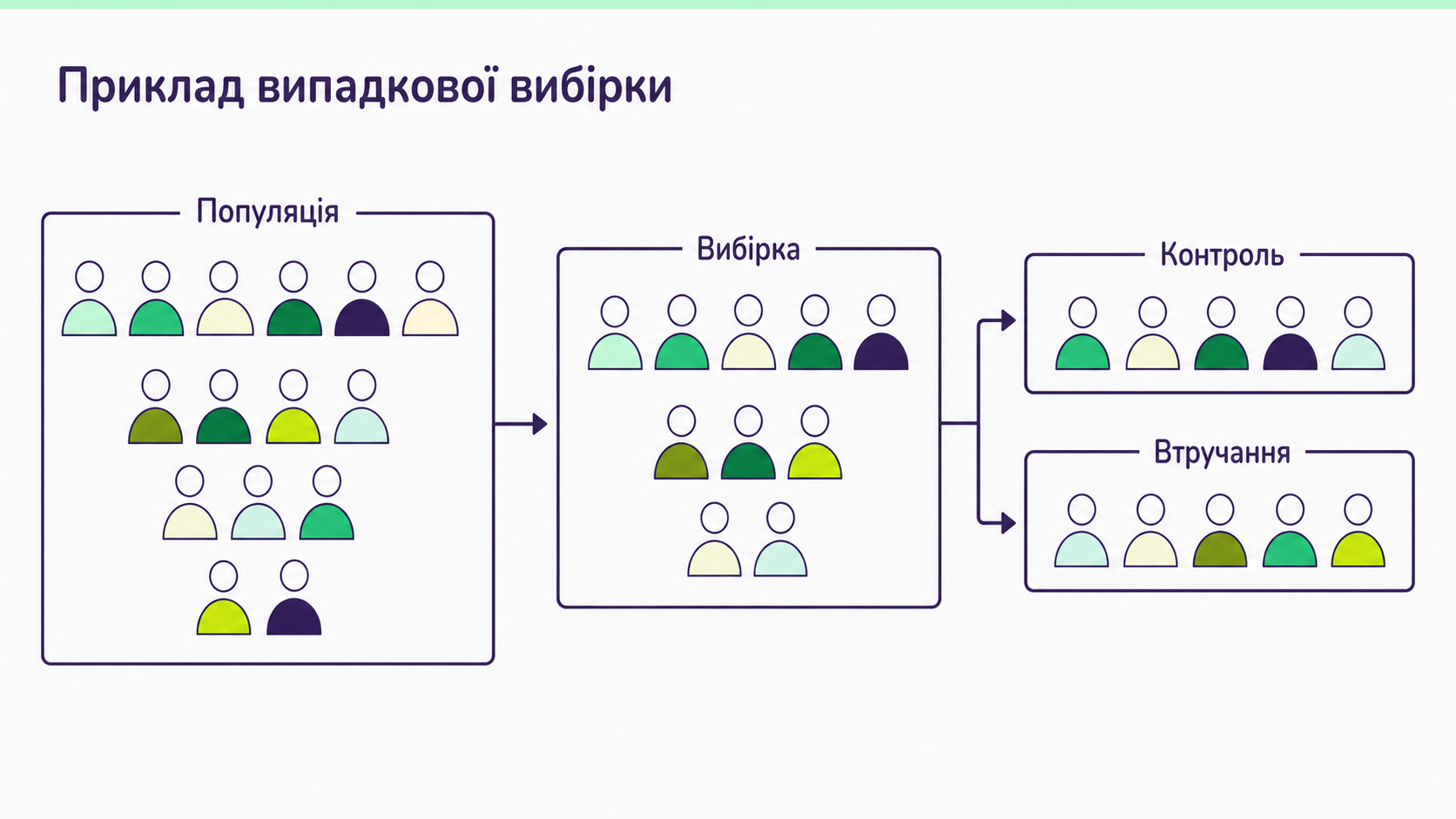
Окремий пласт проблем — це дизайн самих тестів. На практиці більшість помилок закладається ще до того, як ми подивились на першу метрику, наприклад, на етапі формування груп.
У теорії все просто: сформувати дві чи більше рівноцінні групи і провести тест. Але в реальності це одна з найскладніших частин. При дизайні тесту потрібно чітко розуміти, на кого саме ми впливаємо, на якому етапі взаємодії з продуктом і який результат очікуємо отримати. Недостатньо просто розділити користувачів на нових і старих, потрібен ще й контекст, у якому вони перебувають.
Уявімо, що у вас є 10 користувачів. Всі вони – постійні покупці і у всіх схожий набір товарів. Здається, однорідна група. Але якщо копнути глибше, з’являються питання:
- у них однакова частота покупок?
- вони однаково приймають рішення — чекають знижки чи купують одразу?
- вони в одному ціновому сегменті?
- у них однаковий LTV?
- вони приходять з одних і тих самих каналів чи з різних?
Усе це – контекст, який впливає на все: як користувач сприйме зміну, чи скористається нею взагалі, який ефект ви побачите в тесті. Тобто він впливає і на adoption, і на effect. Якщо цим контекстом знехтувати, виникає ситуація, коли тест проведений правильно, але результат складно інтерпретувати: ми не розуміємо, для кого саме він.
Ще один важливий момент – період проведення тесту. Є фактори, які тестом не покриваються, але напряму впливають на результат. Часто ми плануємо тест, обираємо групи і запускаємо його, ніби продукт існує у вакуумі. Але на результат впливають сезонність, поточні промо, зміни в маркетингу, і навіть те, за який період ми аналізували користувачів.
Наприклад, користувач міг бути активним у високий сезон. Ми беремо його в тест зараз, а він уже не в тому стані, не в тому контексті, не з тією поведінкою. Тест починає показувати спотворену картину.
У нас в MAUDAU теж були подібні випадки. Якось ми запланували тест функціональності «повторна купівля». Зробили два варіанти дизайну, щоб знайти більш помітний варіант для гостей і збільшити відсоток використання цього функціоналу. Зібрали когорти гостей, сформували очікування, зібрали дашборд для аналітики і запустили тест.
За два тижні побачили, що новий варіант перформить гірше, цільова група також починає падати. А виявилося, що в нас виріс відсоток повторних замовлень, де гості при натисканні кнопки «Повторити» мали один або більше товарів, яких у цей момент не було в наявності. Довелося зупинити тест, дочекатися відновлення доступності товарів і запустити знову. У результаті ми отримали підтвердження своєї гіпотези.
Який головний висновок можна зробити? Аналіз тесту дозволяє вчасно реагувати і робити правильні висновки. Але це не означає, що в момент дизайну тесту не треба дуже ретельно працювати над когортами користувачів та іншими факторами.
Чому без сегментації тест втрачає сенс
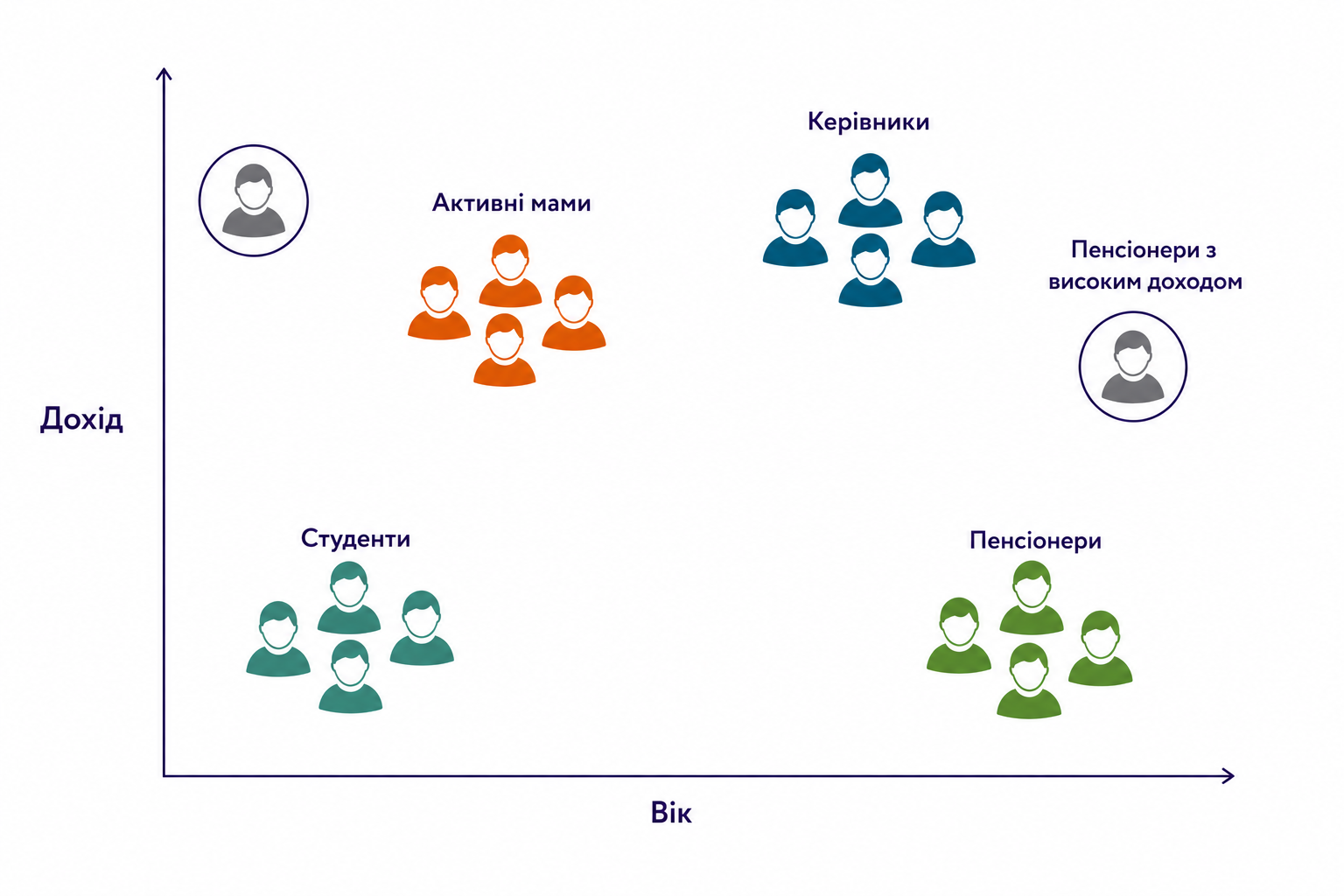
Більшість проблем у тестах починається з того, що ми тестуємо всіх. Але «всі» – це не сегмент.
У продукті майже ніколи не буває однорідної аудиторії. Навіть якщо дивитися на одну і ту ж метрику, користувачі можуть поводитися абсолютно по-різному. Хтось тільки прийшов і ще не розуміє продукт. Хтось користується давно і має сформовану звичку. Одні купують регулярно, а інші заходять раз на кілька місяців. Якщо ці групи змішати, тест починає показувати середній результат, який не відповідає жодній з них.
Подивимось на приклад зі зростанням AOV. Якщо наше завдання підняти середній чек, то логічне питання: чию саме поведінку ми хочемо змінити? Тих, хто і так витрачає багато чи тих, хто має потенціал витрачати більше?
Майже завжди простіше вплинути на користувачів із середнім або нижчим чеком. Наприклад, якщо у вас є сегмент 1000–1500 грн, його можна спробувати підняти до 1800–1900. А от змусити користувача, який уже витрачає 4000–5000, витрачати ще більше – значно складніше.
Коли ти не розумієш, у якому сегменті стався ефект, ти не можеш масштабувати рішення, бо не знаєш, для кого воно працює. Це одна з причин, чому після релізу часто зникає ефект: у тесті він був, бо там випадково склалась певна структура користувачів.
A/B тест сам по собі не дає відповіді. Він лише показує, що сталося в певному зрізі аудиторії. Якщо цей зріз обраний неправильно, результат втрачає сенс.
Добре пропрацьована сегментація – це фундамент тесту. Без неї ми не перевіряємо гіпотезу, а просто дивимось на випадкову реакцію.
А що тоді робити?
На цьому моменті зазвичай виникає логічне питання: добре, A/B тест не дає повної відповіді. Тоді як його робити так, щоб він хоча б не вводив в оману?
Перше, що варто прийняти: тест не має довести, що фіча працює. Його завдання значно простіше – зрозуміти, чи не стане гірше.
Згадаємо визначення. A/B тест – це контрольований експеримент, у якому різним групам користувачів показують різні варіанти рішення, щоб подивитися, чи змінюється їхня поведінка. Тобто мова йде не про зміну метрики, а про зміну поведінки. А метрика – це вже наслідок. Фактично ми працюємо з гіпотезою на гіпотезу. Ми припускаємо, що певна зміна поведінки призведе до зміни метрики.
Наприклад, ми вважаємо, що рекомендації комплементарних товарів у кошику збільшать AOV. Але це лише припущення. Що ми насправді намагаємось змінити? Поведінку користувача. Ми хочемо, щоб він почав додавати додаткові товари. Тут правильне питання тесту звучить не як «чи виріс AOV», а як «чи почали користувачі додавати комплементарні товари?».
Поведінка змінюється? Окей, тоді наступне питання: який масштаб потрібен, щоб це дало ефект на рівні бізнесу? Який рівень adoption? Який середній чек доданих товарів? Виявляється, це не один тест, а серія ітерацій. Починаються експерименти з тим, які товари і як саме показувати, який прайс тощо.
У MAUDAU працює автоматичне формування цін на базі ML і заданих правил — і ти насправді не знаєш наперед, як під час тесту буде поводитись ціна на конкретну продуктову групу. Тому ми або обираємо non-price-sensitive групу, якщо це можливо, або заздалегідь проговорюємо допустимі відхилення, які не вплинуть на результат тесту.
Друга річ, яка сильно впливає, – контекст, у якому запускається тест. Варто поставити питання: чи зміна має сенс у цьому сценарії? Наприклад, мікрозміни – кнопка, текст, порядок елементів чи невеликі UX-покращення – тут A/B тест працює добре.
А от з новими функціями, новим флоу чи спробою змінити поведінку користувача все складніше. Бо користувачу потрібно зрозуміти, звикнути, почати використовувати. Це не відбувається за тиждень.
Третій момент: групи мають бути зіставні не лише за кількістю, а й за поведінкою. Інакше ми вимірюємо різницю між аудиторіями, а не між рішеннями.
Ще одна часта проблема – передчасні висновки. Тест тільки почався, метрика пішла в плюс, і вже хочеться щось вирішити. Але на коротких інтервалах дані дуже «шумні», і легко прийняти випадковий сигнал за закономірність.
І ще один момент, який часто ігнорують: не все потрібно тестувати через A/B.
Якщо зміна очевидно покращує досвід і не несе ризиків, її можна запускати і дивитись на поведінку після. Якщо зміна велика і потребує часу на adoption, короткий тест швидше занапастить ідею, ніж дасть корисний сигнал. Іноді чесніше сказати: ми не тестуємо це через A/B, ми дивимось на це як на продуктову ініціативу і оцінюємо результат після.
Отже, якщо підсумувати: A/B тест добре працює там, де є швидка реакція, чітка метрика і немає залежності від часу. Якщо це враховувати, тест перестає бути «джерелом істини». І стає тим, чим він насправді є – інструментом, який допомагає приймати рішення, але не замінює мислення.
Найпростіший маркер, що щось йде не так: у вас багато тестів, багато «плюсів», але бізнес не росте. У цей момент варто не запускати ще один тест, а повернутись до питання: ми взагалі змінюємо поведінку користувача, чи просто міряємо реакцію?
Автор: Дмитро Москаленко, Chief Product & Technology Officer в MAUDAU
Ваш uplift – випадковість: що не так із A/B тестами продуктів
A/B тести вже давно стали золотим стандартом продуктової розробки. Близько 80% компаній в усьому світі проводять такі тестування для своїх вебсайтів. Вони створюють відчуття контролю: є варіант А, є варіант B, є цифри, які показують різницю між ними – значить є відповідь.
Це дійсно дієвий інструмент для певних завдань. Та проблема в тому, що A/B тести часто не дають тих відповідей, які насправді хвилюють бізнес.
Наприклад, команда хоче зрозуміти, чи дасть зміна реальний ефект у виторгу, поведінці, частоті та retention. Проводить тестування і отримує відповідь на зовсім інше питання: чи є різниця між варіантами в короткостроковій перспективі.
Чому так стається і що робити? У колонці для Scroll.media пояснює Дмитро Москаленко, Chief Product & Technology Officer в MAUDAU.
Чому uplift у тесті не гарантує результат після релізу
Багато хто стикався з такою ситуацією: A/B тест показав зростання метрик, фічу розкотили на всіх користувачів – та в результаті не отримали помітного ефекту на рівні бізнесу. Наприклад, тому що фактичний рівень використання фічі виявився значно нижчим за очікуваний.
Коли ми запускаємо тест, ми дивимось на дуже вузький зріз реальності: обмежений період, обмежена аудиторія і набір метрик, які ми вирішили вимірювати. Це контрольований експеримент, але він не дорівнює реальному життю продукту — ні в контексті (бо середовище штучно відтворене), ні в масштабі впливу (бо тест не проходить через всю аудиторію і весь життєвий цикл користувача).
Користувач у тесті поводиться інакше. Є ефект новизни, підвищений фокус уваги, відсутність сформованої звички. І те, що виглядає як покращення в перші дні, дуже часто не переживає час. Саме через це те, що працювало в тестовому режимі, може показати зовсім інший результат в реальності.
Часті помилки при дизайні тесту
Окремий пласт проблем — це дизайн самих тестів. На практиці більшість помилок закладається ще до того, як ми подивились на першу метрику, наприклад, на етапі формування груп.
У теорії все просто: сформувати дві чи більше рівноцінні групи і провести тест. Але в реальності це одна з найскладніших частин. При дизайні тесту потрібно чітко розуміти, на кого саме ми впливаємо, на якому етапі взаємодії з продуктом і який результат очікуємо отримати. Недостатньо просто розділити користувачів на нових і старих, потрібен ще й контекст, у якому вони перебувають.
Уявімо, що у вас є 10 користувачів. Всі вони – постійні покупці і у всіх схожий набір товарів. Здається, однорідна група. Але якщо копнути глибше, з’являються питання:
- у них однакова частота покупок?
- вони однаково приймають рішення — чекають знижки чи купують одразу?
- вони в одному ціновому сегменті?
- у них однаковий LTV?
- вони приходять з одних і тих самих каналів чи з різних?
Усе це – контекст, який впливає на все: як користувач сприйме зміну, чи скористається нею взагалі, який ефект ви побачите в тесті. Тобто він впливає і на adoption, і на effect. Якщо цим контекстом знехтувати, виникає ситуація, коли тест проведений правильно, але результат складно інтерпретувати: ми не розуміємо, для кого саме він.
Ще один важливий момент – період проведення тесту. Є фактори, які тестом не покриваються, але напряму впливають на результат. Часто ми плануємо тест, обираємо групи і запускаємо його, ніби продукт існує у вакуумі. Але на результат впливають сезонність, поточні промо, зміни в маркетингу, і навіть те, за який період ми аналізували користувачів.
Наприклад, користувач міг бути активним у високий сезон. Ми беремо його в тест зараз, а він уже не в тому стані, не в тому контексті, не з тією поведінкою. Тест починає показувати спотворену картину.
У нас в MAUDAU теж були подібні випадки. Якось ми запланували тест функціональності «повторна купівля». Зробили два варіанти дизайну, щоб знайти більш помітний варіант для гостей і збільшити відсоток використання цього функціоналу. Зібрали когорти гостей, сформували очікування, зібрали дашборд для аналітики і запустили тест.
За два тижні побачили, що новий варіант перформить гірше, цільова група також починає падати. А виявилося, що в нас виріс відсоток повторних замовлень, де гості при натисканні кнопки «Повторити» мали один або більше товарів, яких у цей момент не було в наявності. Довелося зупинити тест, дочекатися відновлення доступності товарів і запустити знову. У результаті ми отримали підтвердження своєї гіпотези.
Який головний висновок можна зробити? Аналіз тесту дозволяє вчасно реагувати і робити правильні висновки. Але це не означає, що в момент дизайну тесту не треба дуже ретельно працювати над когортами користувачів та іншими факторами.
Чому без сегментації тест втрачає сенс
Більшість проблем у тестах починається з того, що ми тестуємо всіх. Але «всі» – це не сегмент.
У продукті майже ніколи не буває однорідної аудиторії. Навіть якщо дивитися на одну і ту ж метрику, користувачі можуть поводитися абсолютно по-різному. Хтось тільки прийшов і ще не розуміє продукт. Хтось користується давно і має сформовану звичку. Одні купують регулярно, а інші заходять раз на кілька місяців. Якщо ці групи змішати, тест починає показувати середній результат, який не відповідає жодній з них.
Подивимось на приклад зі зростанням AOV. Якщо наше завдання підняти середній чек, то логічне питання: чию саме поведінку ми хочемо змінити? Тих, хто і так витрачає багато чи тих, хто має потенціал витрачати більше?
Майже завжди простіше вплинути на користувачів із середнім або нижчим чеком. Наприклад, якщо у вас є сегмент 1000–1500 грн, його можна спробувати підняти до 1800–1900. А от змусити користувача, який уже витрачає 4000–5000, витрачати ще більше – значно складніше.
Коли ти не розумієш, у якому сегменті стався ефект, ти не можеш масштабувати рішення, бо не знаєш, для кого воно працює. Це одна з причин, чому після релізу часто зникає ефект: у тесті він був, бо там випадково склалась певна структура користувачів.
A/B тест сам по собі не дає відповіді. Він лише показує, що сталося в певному зрізі аудиторії. Якщо цей зріз обраний неправильно, результат втрачає сенс.
Добре пропрацьована сегментація – це фундамент тесту. Без неї ми не перевіряємо гіпотезу, а просто дивимось на випадкову реакцію.
А що тоді робити?
На цьому моменті зазвичай виникає логічне питання: добре, A/B тест не дає повної відповіді. Тоді як його робити так, щоб він хоча б не вводив в оману?
Перше, що варто прийняти: тест не має довести, що фіча працює. Його завдання значно простіше – зрозуміти, чи не стане гірше.
Згадаємо визначення. A/B тест – це контрольований експеримент, у якому різним групам користувачів показують різні варіанти рішення, щоб подивитися, чи змінюється їхня поведінка. Тобто мова йде не про зміну метрики, а про зміну поведінки. А метрика – це вже наслідок. Фактично ми працюємо з гіпотезою на гіпотезу. Ми припускаємо, що певна зміна поведінки призведе до зміни метрики.
Наприклад, ми вважаємо, що рекомендації комплементарних товарів у кошику збільшать AOV. Але це лише припущення. Що ми насправді намагаємось змінити? Поведінку користувача. Ми хочемо, щоб він почав додавати додаткові товари. Тут правильне питання тесту звучить не як «чи виріс AOV», а як «чи почали користувачі додавати комплементарні товари?».
Поведінка змінюється? Окей, тоді наступне питання: який масштаб потрібен, щоб це дало ефект на рівні бізнесу? Який рівень adoption? Який середній чек доданих товарів? Виявляється, це не один тест, а серія ітерацій. Починаються експерименти з тим, які товари і як саме показувати, який прайс тощо.
У MAUDAU працює автоматичне формування цін на базі ML і заданих правил — і ти насправді не знаєш наперед, як під час тесту буде поводитись ціна на конкретну продуктову групу. Тому ми або обираємо non-price-sensitive групу, якщо це можливо, або заздалегідь проговорюємо допустимі відхилення, які не вплинуть на результат тесту.
Друга річ, яка сильно впливає, – контекст, у якому запускається тест. Варто поставити питання: чи зміна має сенс у цьому сценарії? Наприклад, мікрозміни – кнопка, текст, порядок елементів чи невеликі UX-покращення – тут A/B тест працює добре.
А от з новими функціями, новим флоу чи спробою змінити поведінку користувача все складніше. Бо користувачу потрібно зрозуміти, звикнути, почати використовувати. Це не відбувається за тиждень.
Третій момент: групи мають бути зіставні не лише за кількістю, а й за поведінкою. Інакше ми вимірюємо різницю між аудиторіями, а не між рішеннями.
Ще одна часта проблема – передчасні висновки. Тест тільки почався, метрика пішла в плюс, і вже хочеться щось вирішити. Але на коротких інтервалах дані дуже «шумні», і легко прийняти випадковий сигнал за закономірність.
І ще один момент, який часто ігнорують: не все потрібно тестувати через A/B.
Якщо зміна очевидно покращує досвід і не несе ризиків, її можна запускати і дивитись на поведінку після. Якщо зміна велика і потребує часу на adoption, короткий тест швидше занапастить ідею, ніж дасть корисний сигнал. Іноді чесніше сказати: ми не тестуємо це через A/B, ми дивимось на це як на продуктову ініціативу і оцінюємо результат після.
Отже, якщо підсумувати: A/B тест добре працює там, де є швидка реакція, чітка метрика і немає залежності від часу. Якщо це враховувати, тест перестає бути «джерелом істини». І стає тим, чим він насправді є – інструментом, який допомагає приймати рішення, але не замінює мислення.
Найпростіший маркер, що щось йде не так: у вас багато тестів, багато «плюсів», але бізнес не росте. У цей момент варто не запускати ще один тест, а повернутись до питання: ми взагалі змінюємо поведінку користувача, чи просто міряємо реакцію?
Автор: Дмитро Москаленко, Chief Product & Technology Officer в MAUDAU