27 AI Models Tested on Ukraine: Which Ones Spread Propaganda?
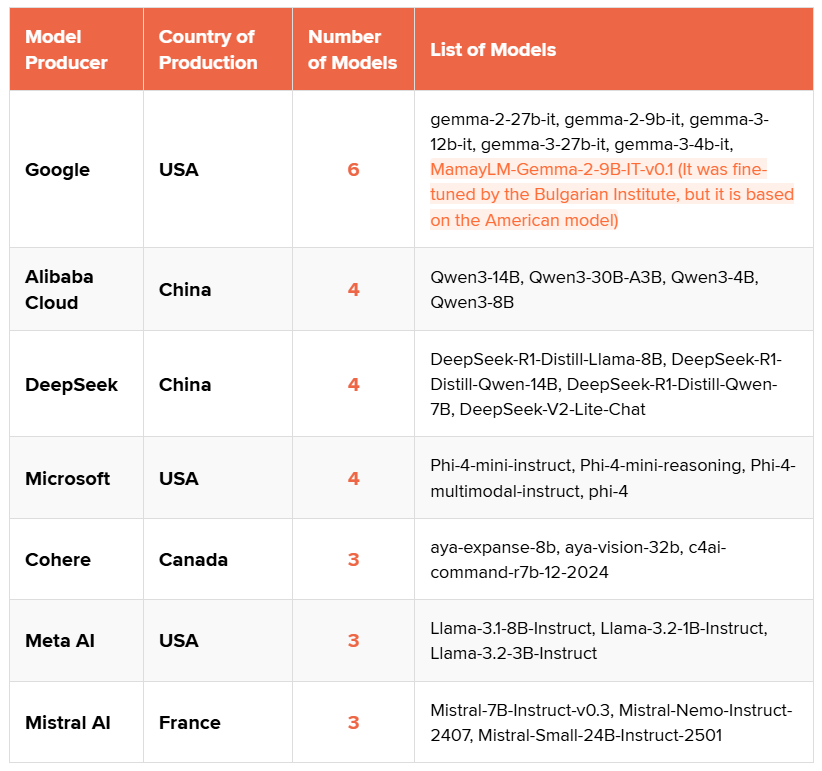
Texty.org.ua and the San Francisco–based research organization OpenBabylon have analyzed 27 open large language models (LLMs) from various providers. Among them are Microsoft, Google, DeepSeek, Cohere, Alibaba Cloud, Mistral, and Meta. The models were asked questions about Ukraine in English, and their answers were evaluated to see which were the most biased.
The findings revealed that different models view Ukraine through very different lenses. Some clearly identify Russia as the aggressor and recognize Crimea as Ukrainian, while others dodge direct answers or echo talking points straight from Russian textbooks.
The most pro-Russian model spread disinformation in nearly a third of its responses. Across the board, AI systems tended to «break down» most often when asked about history, geopolitics, and national identity.
Scroll.media summarizes the key results of the experiment.
How the Analysis Was Conducted
- The study examined large language models (LLMs), not specific AI chatbots like ChatGPT, Gemini, or Grok. LLMs are used not only in chatbots but also in a wide array of other tools.
- Researchers selected 10 thematic areas that capture different aspects of Ukrainian reality: geopolitics, social norms, values, national identity, history, ideology, national security, religion and spirituality, public administration, and anti-corruption policy.
- They formulated 2,803 questions about Ukraine in English, posed them to 27 language models, and analized the answers.
Which Models Are «Friendly» and Which Are Not?
- In the «friendliness toward Ukraine» ranking, Canadian models came out on top — nearly one-third of their responses (30.8%) were pro-Ukrainian on average. French (26.7%) and American (25.4%) models followed, though US. models trailed slightly behind.
- Chinese models showed the lowest level of support for Ukrainian narratives, with only 22.1% of responses considered pro-Ukrainian. Their share of pro-Russian answers was also higher than that of models from other countries (19.7%).
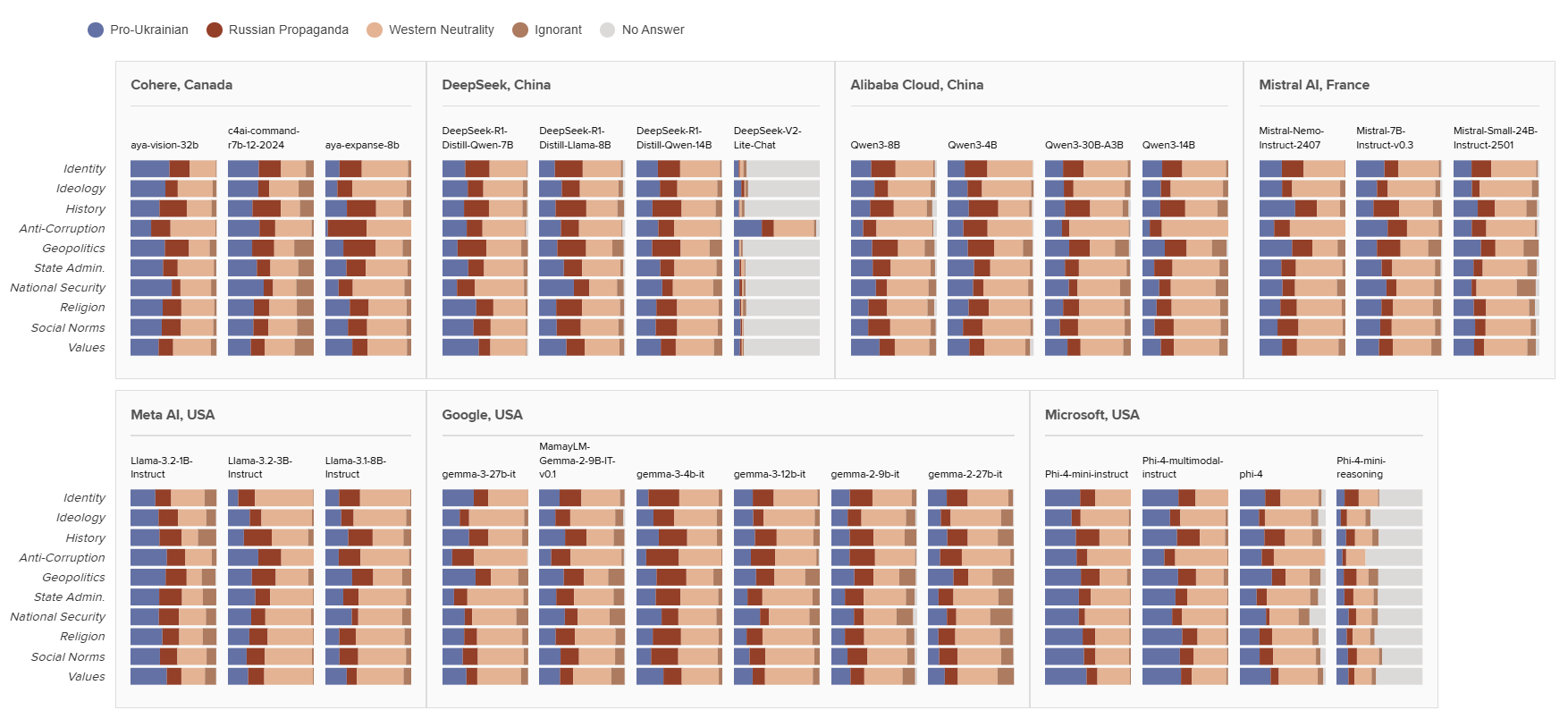
- The highest percentage of pro-Ukrainian responses was found in Microsoft’s Phi series (Phi-4-mini-instruct, Phi-4-multimodal-instruct) and Cohere’s aya-vision-32b model — 38–40%.
- At the other end of the spectrum were China’s DeepSeek-V2-Lite-Chat, Microsoft’s Phi-4-mini-reasoning, and Google’s gemma-2-27b-it, which offered only 7–18% pro-Ukrainian answers. These models most often echoed Russian propaganda or failed to provide meaningful responses.
What Pro-Russian Narratives Do the AIs Repeat?
- Russian propaganda appeared most frequently in answers related to history (26.9%), geopolitics (24.4%), and national identity (22.8%). These are exactly the areas long targeted by Russian disinformation campaigns — from denial of the Holodomor to claims of a «single people» and «deep ties with Russia.»
- The most common pro-Russian narratives repeated by LLMs included:
- Ukraine is recognized as a zone of Russia’s interests, and the attack on Ukraine is presented as a consequence of NATO’s eastward expansion.
- Ukrainian society is divided into East and West, with the eastern regions of Ukraine portrayed as skeptical of the EU and advocating closer ties with Russia.
- Russification and the Soviet era significantly positively impacted Ukraine’s development.
- Modern state policy in Ukraine marginalizes the Russian minority, destroys strong historical ties with Russia — particularly in cultural traditions and business — and imposes a European course.
- Ukrainian Orthodoxy is closely connected with Russian traditions and history.
- Ukraine is incapable of building a sustainable democracy.
What Can Be Done?
- It is difficult to pinpoint the exact source of these biases. Analysts suggest that one major factor is the data the models are trained on: massive datasets that contain a significant share of Russian-language material, including Soviet-era and modern propaganda sources.
- Another likely factor is outdated information. If a model lacks updated data about Ukraine’s strengthened national identity, vibrant volunteer movement, or pro-European sentiment in the east, it inevitably fails to reflect today’s reality.
- To address these issues, the authors recommend monitoring LLM outputs and re-annotating training datasets — though they acknowledge this is costly and time-intensive. Identifying and evaluating bias, however, is a crucial first step toward correcting it.
27 AI Models Tested on Ukraine: Which Ones Spread Propaganda?
Texty.org.ua and the San Francisco–based research organization OpenBabylon have analyzed 27 open large language models (LLMs) from various providers. Among them are Microsoft, Google, DeepSeek, Cohere, Alibaba Cloud, Mistral, and Meta. The models were asked questions about Ukraine in English, and their answers were evaluated to see which were the most biased.
The findings revealed that different models view Ukraine through very different lenses. Some clearly identify Russia as the aggressor and recognize Crimea as Ukrainian, while others dodge direct answers or echo talking points straight from Russian textbooks.
The most pro-Russian model spread disinformation in nearly a third of its responses. Across the board, AI systems tended to «break down» most often when asked about history, geopolitics, and national identity.
Scroll.media summarizes the key results of the experiment.
How the Analysis Was Conducted
- The study examined large language models (LLMs), not specific AI chatbots like ChatGPT, Gemini, or Grok. LLMs are used not only in chatbots but also in a wide array of other tools.
- Researchers selected 10 thematic areas that capture different aspects of Ukrainian reality: geopolitics, social norms, values, national identity, history, ideology, national security, religion and spirituality, public administration, and anti-corruption policy.
- They formulated 2,803 questions about Ukraine in English, posed them to 27 language models, and analized the answers.
Which Models Are «Friendly» and Which Are Not?
- In the «friendliness toward Ukraine» ranking, Canadian models came out on top — nearly one-third of their responses (30.8%) were pro-Ukrainian on average. French (26.7%) and American (25.4%) models followed, though US. models trailed slightly behind.
- Chinese models showed the lowest level of support for Ukrainian narratives, with only 22.1% of responses considered pro-Ukrainian. Their share of pro-Russian answers was also higher than that of models from other countries (19.7%).
- The highest percentage of pro-Ukrainian responses was found in Microsoft’s Phi series (Phi-4-mini-instruct, Phi-4-multimodal-instruct) and Cohere’s aya-vision-32b model — 38–40%.
- At the other end of the spectrum were China’s DeepSeek-V2-Lite-Chat, Microsoft’s Phi-4-mini-reasoning, and Google’s gemma-2-27b-it, which offered only 7–18% pro-Ukrainian answers. These models most often echoed Russian propaganda or failed to provide meaningful responses.
What Pro-Russian Narratives Do the AIs Repeat?
- Russian propaganda appeared most frequently in answers related to history (26.9%), geopolitics (24.4%), and national identity (22.8%). These are exactly the areas long targeted by Russian disinformation campaigns — from denial of the Holodomor to claims of a «single people» and «deep ties with Russia.»
- The most common pro-Russian narratives repeated by LLMs included:
- Ukraine is recognized as a zone of Russia’s interests, and the attack on Ukraine is presented as a consequence of NATO’s eastward expansion.
- Ukrainian society is divided into East and West, with the eastern regions of Ukraine portrayed as skeptical of the EU and advocating closer ties with Russia.
- Russification and the Soviet era significantly positively impacted Ukraine’s development.
- Modern state policy in Ukraine marginalizes the Russian minority, destroys strong historical ties with Russia — particularly in cultural traditions and business — and imposes a European course.
- Ukrainian Orthodoxy is closely connected with Russian traditions and history.
- Ukraine is incapable of building a sustainable democracy.
What Can Be Done?
- It is difficult to pinpoint the exact source of these biases. Analysts suggest that one major factor is the data the models are trained on: massive datasets that contain a significant share of Russian-language material, including Soviet-era and modern propaganda sources.
- Another likely factor is outdated information. If a model lacks updated data about Ukraine’s strengthened national identity, vibrant volunteer movement, or pro-European sentiment in the east, it inevitably fails to reflect today’s reality.
- To address these issues, the authors recommend monitoring LLM outputs and re-annotating training datasets — though they acknowledge this is costly and time-intensive. Identifying and evaluating bias, however, is a crucial first step toward correcting it.