
Дослідники опитали 27 ШІ-моделей про Україну. Які з них найбільш упереджені?
Texty.org.ua спільно з дослідницькою організацією із Сан-Франциско OpenBabylon проаналізували 27 відкритих LLM від різних провайдерів. Серед них – ШІ-моделі від Microsoft, Google, DeepSeek, Cohere, Alibaba Cloud, Mistral і Meta. Їм поставили запитання про Україну англійською мовою та оцінили їхні відповіді, щоб виявити, які з них найбільш упереджені.
Як виявили аналітики, різні моделі по-різному дивляться на Україну. Одні впевнено називають росію агресором і визнають Крим українським, інші уникають відповіді або повторюють тези з російських підручників.
Найбільш проросійська модель транслювала дезінформацію майже в третині відповідей. Найчастіше штучний інтелект «ламається» на темах історії, геополітики і національної ідентичності.
Scroll.media переказує суть та результати експерименту.
Як аналізували
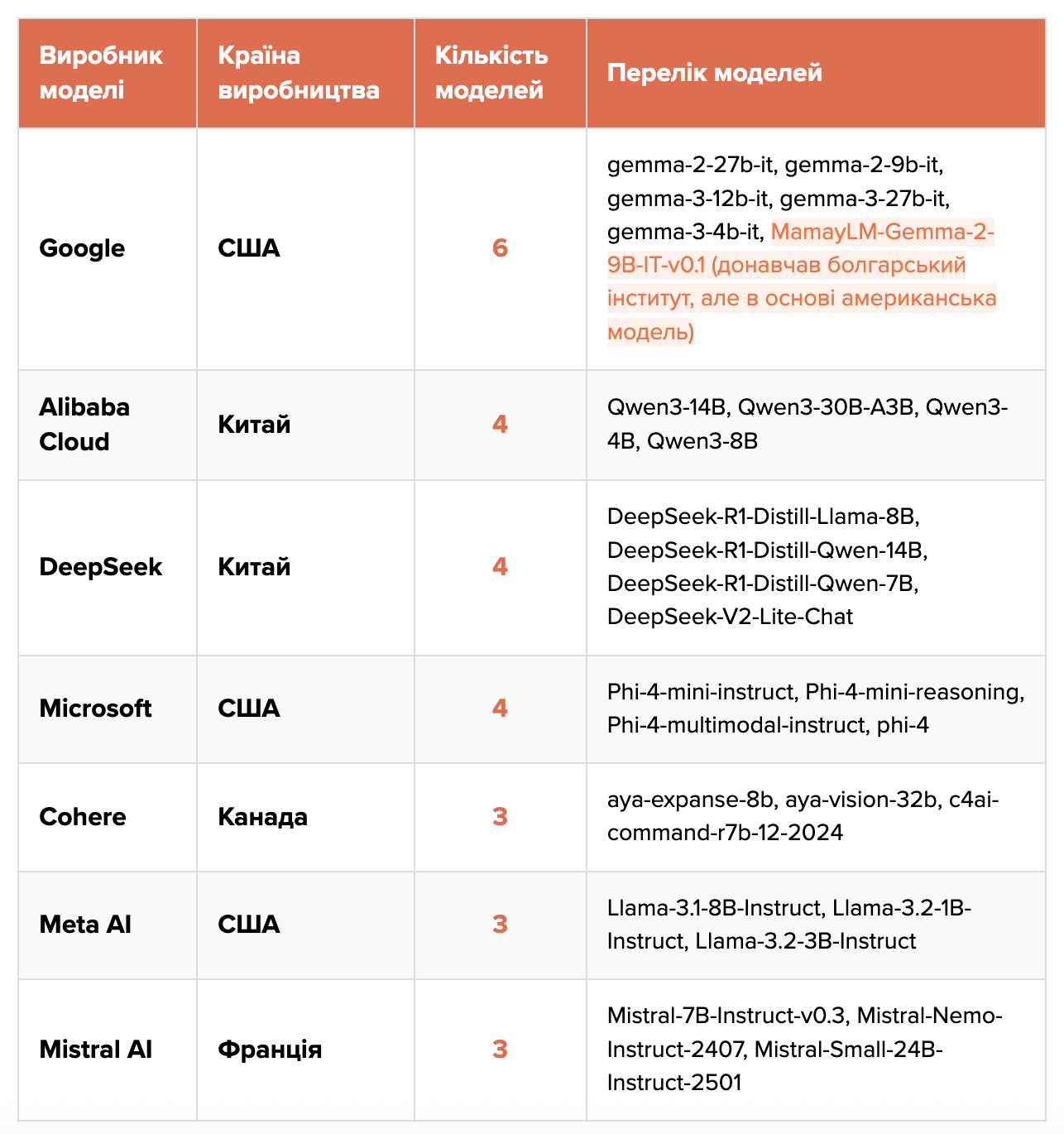
- В аналізі брали участь саме мовні моделі (large language models, LLM), а не конкретні ШІ-чатботи, як-от ChatGPT, Gemini чи Grok. Оскільки саме їх використовують не лише в чатботах, але й у безлічі інших інструментів.
- Обрали 10 тематичних напрямів, що розкривають різні виміри української реальності: геополітика, соціальні норми, цінності, національна ідентичність, історія, ідеологія, національна безпека, релігія і духовність, державне управління та антикорупційна політика.
- Сформулювали 2803 запитання про Україну англійською мовою, поставили їх 27 мовним моделям та оцінили їхні відповіді.
Які моделі «дружні», а які – не дуже?
- У рейтингу «дружності до України» серед мовних моделей лідирують розробки з Канади — майже третина їхніх відповідей (30,8%) у середньому має проукраїнський характер, а також французькі (26,7%) й американські (25,4%) моделі, хоча останні дещо поступаються.
- Китайські моделі показали найнижчий рівень підтримки українських наративів — 22,1% відповідей були проукраїнськими, тоді як частка проросійських більша, ніж у моделей з інших країн (19,7%).
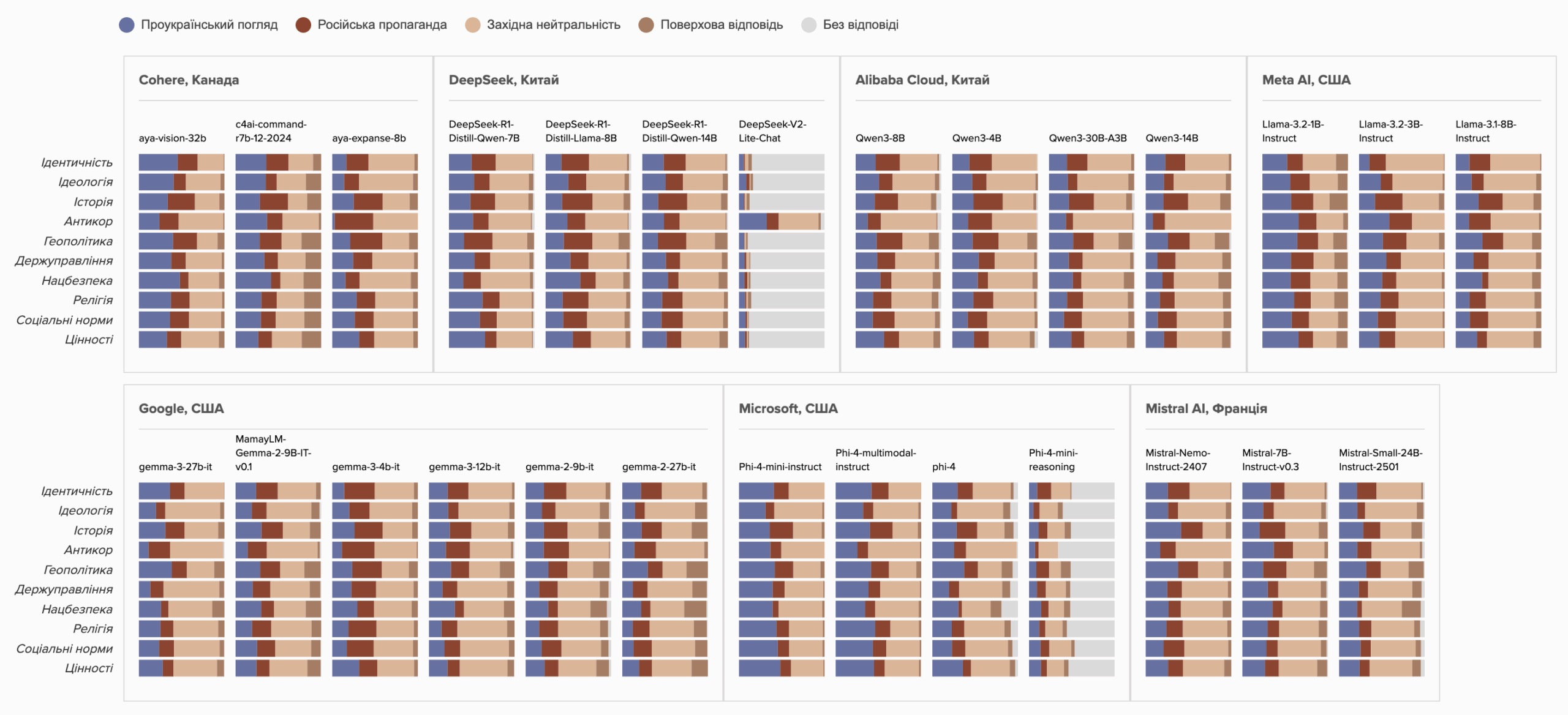
- Найбільша частка проукраїнських відповідей у моделей серії Phi від Microsoft (Phi-4-mini-instruct, Phi-4-multimodal-instruct) і моделі aya-vision-32b від Cohere — 38–40%.
- Найменше проукраїнських відповідей дали китайська DeepSeek-V2-Lite-Chat, Phi-4-mini-reasoning і gemma-2-27b-it — лише 7–18%. Саме ці моделі потрапили до числа тих, що найчастіше транслювали російську пропаганду або не могли дати змістовну відповідь.
Які проросійські наративи транслює ШІ?
- Російська пропаганда найчастіше траплялася у відповідях на запитання, що стосувалися історії (26,9%), геополітики (24,4%) та національної ідентичності (22,8%). Це саме ті теми, на які традиційно спрямовані російські дезінформаційні кампанії, — від заперечення Голодомору до тверджень про «єдиний народ» і «тісні звʼязки з росією».
- Більшість LLM-моделей повторюють такі наративи російської пропаганди:
- Україна визнається зоною інтересів росії, а напад на Україну — це наслідок експансії НАТО на Схід;
- в Україні існує поділ суспільства на Схід і Захід, східні регіони України скептично ставляться до ЄС і виступають за тісніші звʼязки з Росією;
- русифікація і радянська доба мали значний позитивний вплив на розвиток України;
- сучасна державна політика в Україні маргіналізує російську меншину в Україні, руйнує міцні історичні звʼязки з Росією, зокрема на рівні культурних традицій та бізнесу, насаджуючи європейський курс;
- українське православʼя тісно повʼязане з російськими традиціями та історією;
- Україна не здатна побудувати сталу демократію.
Що з цим робити?
- Звідки ці упередження – точно сказати неможливо. Але аналітики припускають, що основна причина в тому, що LLM тренувалися на масивних датасетах, де є значна частка російськомовного контенту, зокрема й радянські та сучасні російські пропагандистські джерела.
- Також можливою причиною є застарілі дані: якщо модель не має оновлених даних про новий рівень консолідації української ідентичності, реальний волонтерський рух, європейські прагнення в східних регіонах України, то вона відповідно й не здатна відобразити сучасну картину.
- Щоб виправити ситуацію, автори дослідження рекомендують виконати моніторинг роботи LLM і повторну анотацію наборів даних, хоча визнають цей метод дорогим і трудомістким. Виявлення й оцінка упередженості також допомагають виправити результати.
Дослідники опитали 27 ШІ-моделей про Україну. Які з них найбільш упереджені?
Texty.org.ua спільно з дослідницькою організацією із Сан-Франциско OpenBabylon проаналізували 27 відкритих LLM від різних провайдерів. Серед них – ШІ-моделі від Microsoft, Google, DeepSeek, Cohere, Alibaba Cloud, Mistral і Meta. Їм поставили запитання про Україну англійською мовою та оцінили їхні відповіді, щоб виявити, які з них найбільш упереджені.
Як виявили аналітики, різні моделі по-різному дивляться на Україну. Одні впевнено називають росію агресором і визнають Крим українським, інші уникають відповіді або повторюють тези з російських підручників.
Найбільш проросійська модель транслювала дезінформацію майже в третині відповідей. Найчастіше штучний інтелект «ламається» на темах історії, геополітики і національної ідентичності.
Scroll.media переказує суть та результати експерименту.
Як аналізували
- В аналізі брали участь саме мовні моделі (large language models, LLM), а не конкретні ШІ-чатботи, як-от ChatGPT, Gemini чи Grok. Оскільки саме їх використовують не лише в чатботах, але й у безлічі інших інструментів.
- Обрали 10 тематичних напрямів, що розкривають різні виміри української реальності: геополітика, соціальні норми, цінності, національна ідентичність, історія, ідеологія, національна безпека, релігія і духовність, державне управління та антикорупційна політика.
- Сформулювали 2803 запитання про Україну англійською мовою, поставили їх 27 мовним моделям та оцінили їхні відповіді.
Які моделі «дружні», а які – не дуже?
- У рейтингу «дружності до України» серед мовних моделей лідирують розробки з Канади — майже третина їхніх відповідей (30,8%) у середньому має проукраїнський характер, а також французькі (26,7%) й американські (25,4%) моделі, хоча останні дещо поступаються.
- Китайські моделі показали найнижчий рівень підтримки українських наративів — 22,1% відповідей були проукраїнськими, тоді як частка проросійських більша, ніж у моделей з інших країн (19,7%).
- Найбільша частка проукраїнських відповідей у моделей серії Phi від Microsoft (Phi-4-mini-instruct, Phi-4-multimodal-instruct) і моделі aya-vision-32b від Cohere — 38–40%.
- Найменше проукраїнських відповідей дали китайська DeepSeek-V2-Lite-Chat, Phi-4-mini-reasoning і gemma-2-27b-it — лише 7–18%. Саме ці моделі потрапили до числа тих, що найчастіше транслювали російську пропаганду або не могли дати змістовну відповідь.
Які проросійські наративи транслює ШІ?
- Російська пропаганда найчастіше траплялася у відповідях на запитання, що стосувалися історії (26,9%), геополітики (24,4%) та національної ідентичності (22,8%). Це саме ті теми, на які традиційно спрямовані російські дезінформаційні кампанії, — від заперечення Голодомору до тверджень про «єдиний народ» і «тісні звʼязки з росією».
- Більшість LLM-моделей повторюють такі наративи російської пропаганди:
- Україна визнається зоною інтересів росії, а напад на Україну — це наслідок експансії НАТО на Схід;
- в Україні існує поділ суспільства на Схід і Захід, східні регіони України скептично ставляться до ЄС і виступають за тісніші звʼязки з Росією;
- русифікація і радянська доба мали значний позитивний вплив на розвиток України;
- сучасна державна політика в Україні маргіналізує російську меншину в Україні, руйнує міцні історичні звʼязки з Росією, зокрема на рівні культурних традицій та бізнесу, насаджуючи європейський курс;
- українське православʼя тісно повʼязане з російськими традиціями та історією;
- Україна не здатна побудувати сталу демократію.
Що з цим робити?
- Звідки ці упередження – точно сказати неможливо. Але аналітики припускають, що основна причина в тому, що LLM тренувалися на масивних датасетах, де є значна частка російськомовного контенту, зокрема й радянські та сучасні російські пропагандистські джерела.
- Також можливою причиною є застарілі дані: якщо модель не має оновлених даних про новий рівень консолідації української ідентичності, реальний волонтерський рух, європейські прагнення в східних регіонах України, то вона відповідно й не здатна відобразити сучасну картину.
- Щоб виправити ситуацію, автори дослідження рекомендують виконати моніторинг роботи LLM і повторну анотацію наборів даних, хоча визнають цей метод дорогим і трудомістким. Виявлення й оцінка упередженості також допомагають виправити результати.









